
Inhaltsverzeichnis
In unserem Beitrag zum Migrationsprozess haben wir bereits gezeigt, wie wir bei einer automatisierten Migration in sechs Schritten zum Ziel kommen. Am Anfang steht dabei zunächst das Verstehen der verschiedenen Datenstrukturen von Quelle und Ziel – dieser Schritt ist der Dreh- und Angelpunkt eines Migrationsprojekts. Und der Rest ist dann noch etwas Skriptmagie. Also: Zauberstäbe raus und „Hex-Hex“ oder „Aparecium“ *.
Am Anfang war das proprietäre Quellformat
Auf unserem Weg gilt es zwei Dinge einzusammeln: Die Grafiken und die Texte. Grafiken in InDesign liegen im proprietären AI-Format vor, welches zu einem späteren Zeitpunkt in SVG o. Ä. umgewandelt wird. Die Grafiken können so nach ST4 übernommen werden. Nicht vergessen dürfen Sie bei der Migration die Grafikverweise im Content. Diese Referenzen müssen beim Überführen in ST4 entsprechend neu gezogen werden.
Strukturell betrachtet baut InDesign auf eine zentrale Einheit: das Dokument. Ein Dokument umfasst häufig nur ein Kapitel der gesamten Anleitung. Innerhalb eines solchen Dokuments finden wir Querverweise, Grafikreferenzen, einzelne Textframes, Variablen etc. Alles, was eine Dokumentation eben so mit sich bringt. Unser Ziel ist es, das gesamte Werk in einer einzigen XML-Datei zusammenzuführen, um diese dann in eine ST-Import-Datei (STI) umzuwandeln und nach SCHEMA ST4 zu importieren. Auf geht’s!
Begeben wir uns einen Schritt tiefer, auf Datenebene: Dort ist ein InDesign-Dokument als IMDD-Datei gespeichert. Über ein frei zugängliches Tool lässt sich diese jedoch in ein XML-basiertes Austauschformat (IDML) umwandeln. Diese IDML-Dateien fassen wir mit einem von uns programmierten Skript in einer großen XML-Datei zusammen. Hierbei werden einzelne Informationen bereits sortiert und gefiltert; wir extrahieren z. B. eine Liste aller Variablen und identifizieren identische Icons und führen sie gleich zusammen.
Jetzt haben wir schonmal alle nötigen Daten in einer einzelnen XML-Datei für den anstehenden SCHEMA ST4-Import extrahiert. Vor dem Import müssen wir diese Datei aber noch etwas transformieren.
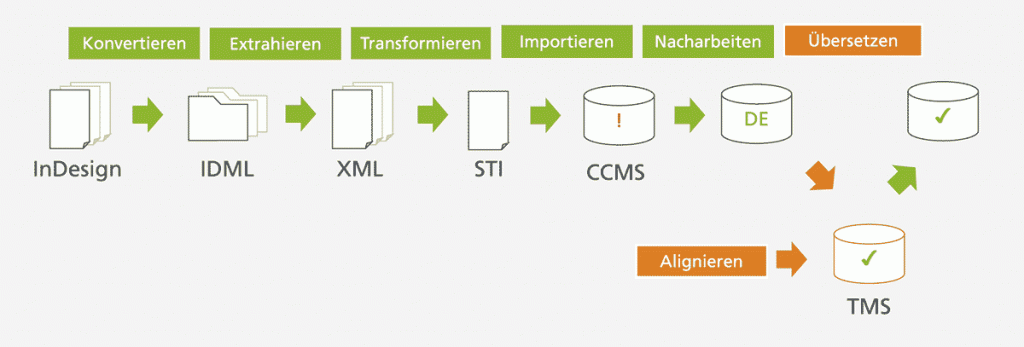
Ablauf der Migration von InDesign nach SCHEMA ST4
Magische Kaskade: Die große Verwandlung in kleinen Schritten
Wie mit allen großen Projekten ist es auch hier ratsam, die Umwandlung in kleine Aufgaben zu unterteilen. Deswegen fließt die XML-Datei durch eine mehrstufige XSLT-Kaskade, die den Content nach und nach so umbaut, dass er mit dem Datenmodell von SCHEMA ST4 kompatibel ist. XSLT ist übrigens eine Programmiersprache speziell zur Transformation von – Sie ahnen es – XML-Dateien. Diese XSLT-Kaskade passen wir individuell den Anforderungen im Projekt und dem Aufbau der Quelldaten an.
In unserer Kaskade fangen wir beim Gröbsten an und ermitteln zunächst Absätze und Zeichenformat-Bereiche. Das kann herausfordernd sein, weil InDesign layout-orientiert arbeitet. Semantisch zusammenhängende Informationen finden sich hier oft über die Textspalte hinweg und brauchen deshalb besondere Aufmerksamkeit. Ein Beispiel sind Informationen oder Grafiken in der Marginalie (Seitenspalte). Auch Warnhinweise sind auf Datenebene häufig nur als zweispaltige Tabellen angelegt und damit schwer unterscheidbar von anderen Informationen, die gleich aufgebaut sind:
 Beispiel für ein Bild in der Marginalspalte
Beispiel für ein Bild in der Marginalspalte Beispiel für Warnhinweise als zweispaltiges Tabellenkonstrukt
Beispiel für Warnhinweise als zweispaltiges TabellenkonstruktDanach gehen wir die Kaskade Schritt für Schritt weiter. Dabei verwendet die Kaskade immer das Ergebnis des vorherigen Schrittes. Das hat den großen Vorteil, dass man klar und sauber abgrenzen kann, was verarbeitet wird. So werden nacheinander:
- Die Hierarchien und Schachtelungen erfasst,
- die Querverweise mit eindeutigen IDs identifiziert, um sie später auch in ST4 auflösen zu können,
- Tabellen bereinigt und in das Tabellenmodell von ST4 überführt,
- einzelne Bausteine durch die zuvor erkannten Hierarchien und Schachtelungen zusammengestellt (Kapitel, Unterkapitel, Zwischenüberschriften, Absätze, Listenpunkte etc.),
- der textliche Inhalt bereinigt (z. B. Symbole nach Unicode übernommen, Tabulatoren werden entfernt, Grafikreferenzen auf unsere zuvor vergebenen IDs angepasst etc.) und
- schlussendlich liegt der Content im Zielformat (STI) vor.
Die Anzahl der Skripte und was sie im Einzelnen leisten, ist nicht in Stein gemeißelt. Es hängt stark von den Quelldaten ab, wie gut sich Regeln finden und Ausnahmen abgreifen lassen. In Hinblick auf die Verminderung manueller Nacharbeiten ist noch einiges möglich. So lassen sich skriptbasiert gleiche Inhalte filtern, z. B. in Warnhinweisen. Schon während des Migrationsprozesses legen Sie so den Grundstein für die Wiederverwendungen in SCHEMA ST4, wodurch sich manuelle Arbeiten deutlich verkürzen. Ganz ohne manuelles Nacharbeiten geht es leider nicht. Hierunter fallen bekannte QS-Themen, wie das Prüfen der oben erwähnten semantischen Einheiten (Warnhinweise, Handlungsanweisungen etc.) oder auch das Alignment im Translation Memory System (TMS), bei einem mehrsprachigen Import.
Und wer jetzt neugierig ist und diesen Import einmal live sehen möchte, der nimmt sich jetzt eine Minute Zeit, denn länger dauert der eigentliche Import oft gar nicht. In unserem Beispiel zeigen wir den Import von mehreren Dutzend Betriebsanleitungen inklusive Grafiken, Links, Variablen und Wiederverwendungen.

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Fazit
Wie wir bereits in unserem Blogartikel Migration von InDesign ins CMS vorgerechnet haben, kann sich eine voll- oder teilautomatisierte Migration im großen Maßstab rechnen. Aber das Projekt muss keine 2500 Seiten Doku umfassen, damit sich dieser automatisierte Ansatz lohnt. Bereits ab 3–4 Anleitungen kann die manuelle Migration die teilautomatisierte preislich übersteigen und sich der Einsatz von Skripten lohnen. Das gilt jedoch nur, wenn Sie auf Expertenwissen zugreifen können. Denn zum Erstellen einer solchen Kaskade sind neben XML/ XSLT-Kenntnissen auch ein solides Hintergrundwissen der Quell- und Zielformaten notwendig. Lassen Sie sich hier im Zweifelsfall von einem erfahrenen Dienstleister beraten, um die Aufwände konkret abschätzen zu können und eine fundierte Entscheidung zu treffen. Wir helfen Ihnen hier gerne weiter!
* „Aparecium“ ist ein Zauberspruch aus dem Harry-Potter-Universum, der Verborgenes enthüllt – wenn das nicht zu unserem Thema passt!


