
Inhaltsverzeichnis
Im September haben wir unseren Nachwuchspreis Berufliche Kommunikation verliehen. Traditionell schreiben die Preisträger:innen in unserem Blog einen Gastbeitrag und stellen ihre Arbeit vor. Das hat Alexander Holste bereits in seinem Gastartikel „Effiziente Lasten- oder Pflichtenhefte in interfachlichen Projekten erstellen“ getan und so haben wir uns verständigt, dass er seine neuesten Forschungen zu Chatbots und Automatischen Maschinellen Übersetzungen (AÜM) bei uns präsentiert, sozusagen frisch von der tekom direkt in unser Blog. Wir freuen uns sehr und gratulieren Herrn Holste noch einmal herzlich zum Gewinn!

Natural Language Processing bietet vermeintlich viele Vorteile für ein Unternehmen: zum Beispiel automatisierte Antworten auf standardisierbare Anfragen von Klient/-innen durch die freundliche Persona eines Chatbots und die synchrone Live-Übersetzung der Unternehmenshomepage in eine beliebige Sprache mittels Automatisierter Maschineller Übersetzung (Google Translate, DeepL, …).
Zahlt sich der Einsatz solcher Maschinen aber aus? Dazu sind Kriterien zu bestimmen, die den wirtschaftlichen Erfolg messen können. Eines vorab: Der wirtschaftliche Erfolg ist abhängig vom kommunikativen Erfolg und im Zusammenhang damit natürlich vom Imagegewinn/-verlust für das Unternehmen, der aus dem Einsatz der Maschinen resultiert! Diese praktischen Überlegungen waren der Ausgangspunkt für meinen Vortrag „Argumentieren mit Chatbots, in MÜ und Automated Content Scoring“ bei der tekom-Jahrestagung. Entsprechend lässt sich die Frage nach dem wirtschaftlichen Erfolg in Abhängigkeit vom kommunikativen Erfolg vor dem Hintergrund der aktuellen Wissenskommunikationsforschung reformulieren: Bietet der von einer Maschine ausgegebene Text die Grundlage, auf der Klient/-innen ihr „Wissensdefizit“ (Wissensasymmetrie) ausgleichen können, das der Anlass für ihre Kontaktaufnahme war?
Wie der Vortragstitel andeutet, eignet sich die Textebene Argumentation als Kriterium, um diese Frage zu beantworten.
Was allgemein als Argumentation bekannt ist, lässt sich wiederum vor dem Hintergrund der Wissenskommunikationsforschung in Form von unterschiedlichen Komplexitätsgraden eines semantischen Netzwerkes (Engberg/Heller 2020) erfassen, die in einem Text enthalten sind (s. Abbildung 1; Beispiel unten).
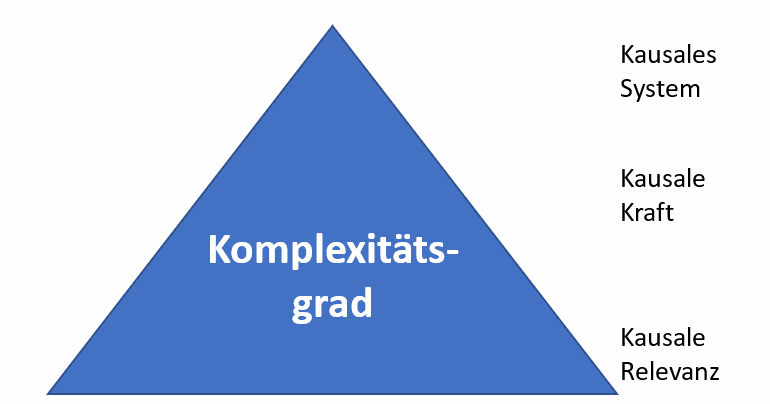 Komplexitätsgrad des semantischen Netzwerks innerhalb eines Kommunikats (Eigene Darstellung in Anlehnung an Engberg/Heller 2020)
Komplexitätsgrad des semantischen Netzwerks innerhalb eines Kommunikats (Eigene Darstellung in Anlehnung an Engberg/Heller 2020)Messung des kommunikativen Erfolges
Der kommunikative Erfolg kann dann in zwei Qualitätsstufen gemessen werden:
- Stufe 1: Der Komplexitätsgrad des semantischen Netzwerks eignet sich als Messinstrument, um einschätzen zu können, ob der Text die Klient/-innen dazu befähigt, ihre betreffende Wissensasymmetrie ausgleichen können. Bezogen auf institutionelle Kommunikation ist damit auch die Frage verbunden, ob die Maschine die Erwartungen der Klient/-innen erfüllt, also ob die Klient/-innen zufrieden sind und der Einsatz der Maschine indirekt die Imagefunktion der Unternehmensmarke (Kastens/Lux 2014: 19) unterstützt oder unterminiert.
- Stufe 2: Der ausgegebene Text der Maschine ist rechtssicher, sodass aus dieser Antwort keine Haftungsansprüche resultieren, die ja durchaus den einen oder anderen Euro kosten können. Denn hinter jeder Maschine stehen deren Entwickler/-innen, die letztlich auch für die Text-Ausgabe der Maschine haftbar gemacht werden können (Hoeren 2018).
Bevor es zum Beispiel geht, zwei Dinge vorab:
- Betrachten wir Natural Language Processing – also die Verarbeitung und Gestaltung von historisch gewachsenen Sprachen wie dem Deutschen oder Englischen, die wir Menschen im Alltag gebrauchen – zeichnen sich Maschinen dadurch aus, dass sie im Gegensatz zu uns weder über ein Weltwissen noch über ein Bewusstsein verfügen (Lotze 2019). D. h., wenn etwa eine Verordnung aktualisiert wird, die für die jeweilige Kommunikationssituation relevant ist, ist die Maschine nicht imstande, ihre Antwort-Textbausteine diesbezüglich selbstständig zu aktualisieren. Dementsprechend verstehen Maschinen nicht einmal das, was sie selbst sagen (Wendland 2020). Schon mancher hat sich einmal den Spaß erlaubt, die Speisekarte des Lieblingsrestaurants von Google Translate in eine Sprache übersetzen und dann zurückübersetzen zu lassen. Aufgrund des mangelnden Weltwissens und des mangelnden Bewusstseins fehlen Maschinen die wesentlichen Voraussetzungen für Kommunikation, sodass man stattdessen allgemein auch von Maschine-Mensch-Interaktion spricht.
- Maschinen können grob in datenbasierte Systeme, meist sogenannte KIs, und in regelbasierte Maschinen eingeteilt werden (Jurafsky/Martin 2020: 168 ff.). KIs nehmen Zuordnungen und Verknüpfungen vereinfacht dargestellt auf der Grundlage von Nutzerdaten und vorhandenen Algorithmen irgendwann selbst vor, müssen dazu aber von Entwickler/-innen noch trainiert werden. Die Maschine ist in diesem Zusammenhang wie eine Black Box zu betrachten, was gezielte Eingriffe unmöglich macht. Einzelne fehlerhaft ausgegebene Texte lassen sich daher nicht einfach ändern. Dies macht es unmöglich, mit KIs rechtssichere Texte zu erstellen. Daher sind eher regelbasierte Maschinen geeignet, um rechtssichere Texte zu produzieren.
Ein Beispiel aus der institutionellen Kommunikation
Kommen wir zu einem Beispiel institutioneller Kommunikation, das zeigt, wie sich der ausgegebene Text einer Maschine durch den Komplexitätsgrad eines semantischen Netzwerks erfassen lässt. Die folgende Tabelle enthält den zentralen Satz zur Corona-Regelung, zu finden auf der offiziellen Hilfe-Seite der Stadt Düsseldorf. Auf dieser Homepage ist eine synchrone Automatisierte Maschinelle Übersetzung mittels Google Translate möglich, die dort technisch mit einer sogenannten API verknüpft ist. Ausgangstext ist das Original auf Deutsch (AT), den die Seite automatisiert in den Zieltext auf Englisch (ZT1) und auf Italienisch (ZT2) übersetzt hat.
 Zentraler Satz auf städtischer Corona-Hilfsseite: Deutsch/Englisch/Italienisch (Holste 2022a).
Zentraler Satz auf städtischer Corona-Hilfsseite: Deutsch/Englisch/Italienisch (Holste 2022a).Das Beispiel der italienischen Übersetzung wird herangezogen, um zu zeigen, dass sich der zentrale Fehler in der englischen Übersetzung vermutlich in diverse andere Sprachen überträgt, die auf der Seite mittels Google Translate übersetzt werden: aus „offen … stehen“ wird „are“, ein sogenanntes generic verb mit einer sehr unspezifischen Bedeutung, da die Maschine vermutlich keine Entsprechung zu „offenstehen“ gefunden oder den Zusammenhang zwischen „stehen … offen“ nicht erkannt hat. Denn üblicherweise nutzen maschinelle Übersetzungen eine sogenannte Zwischensprache, über die ausgehend von der Ausgangssprache in die Zielsprache übersetzt wird (Schubert 2007). Dieses Vorgehen spart Sprachenkombinationen, die in der Maschine hinterlegt sein müssen. Englisch gilt als die zentrale Zwischensprache, sodass ein Fehler bezogen auf sie für alle weiteren relevant wird.
Schauen wir uns die beiden Qualitätsstufen an, die im Beispiel erreicht werden.
Auffällig wird an dem Beispielsatz, dass bereits der deutschsprachige Ausgangstext an einem wesentlichen Punkt krankt: die Verbindungswörter „und“ bzw. „sowie“ lassen offen, ob eine Person alle drei Bedingungen erfüllen muss (geimpft, genesen, getestet) oder nur eine davon (s. gelbe Pfeile in Abbildung 3). Diese Frage ist zentral, um das Anliegen der Klient/-innen zu klären. Ein Humanübersetzer hätte dies bereits mit den Fachleuten aus der zuständigen Abteilung klären können, also ein sogenanntes Pre-Editing vornehmen können. Die Verbindungswörter „und“ bzw. „sowie“ würden dann durch ein ausschließendes „oder“ ersetzt werden.
Stufe 1: Dass aus „stehen … offen“ das englische „are“ wird, wäre ein klarer Fall für ein sogenanntes Post-Editing durch einen Menschen (s. gelbe Kästchen in Abbildung 3): Der Dreischritt juristischer Texte ‘Bedingung – Konsequenz – Ausnahme’ (Engberg/Heller 2020) findet sich auch im zentralen Beispielsatz der Stadt (s. Abbildung 3). In der englischen Fassung bleibt aber vollkommen unklar, welche Konsequenz aus der Erfüllung der gesetzlichen Vorgaben (geimpft, genesen, getestet) folgen. Der deutschsprachige Satz erreicht den mittlere Komplexitätsgrad der kausalen Kraft, demzufolge ein Element ursächlich für ein anderes ist. Der Dreischritt ‘Bedingung – Konsequenz – Ausnahme’ ist in der englischen Übersetzung, wie gezeigt, unvollständig. Hier kann also bezogen auf das Anliegen der Klient/-innen gar kein Komplexitätsgrad bestimmt werden! Wie zufrieden die Klient/-innen dann sind, kann sich jeder selbst ausmalen.
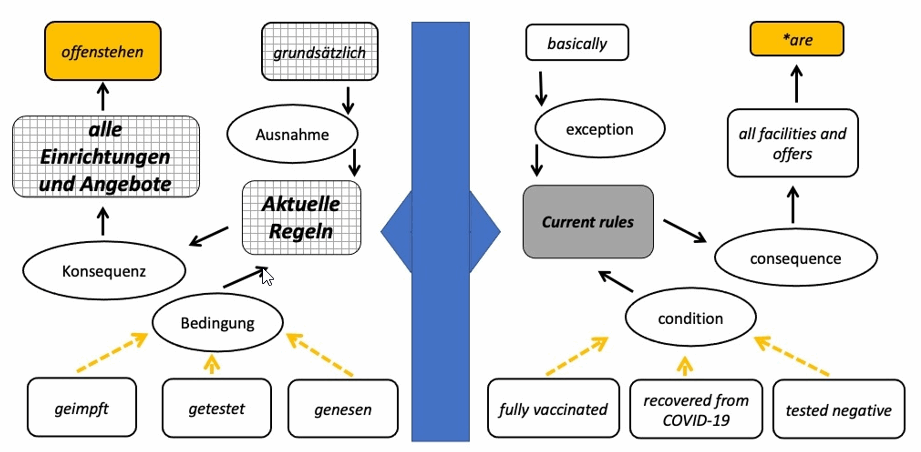 Semantisches Netzwerk zu städtischer Corona-Hilfsseite (Holste 2022a).
Semantisches Netzwerk zu städtischer Corona-Hilfsseite (Holste 2022a).Stufe 2: Da das semantische Netzwerk unvollständig ist, wird deutlich, dass die Maschine keinen rechtssicheren Text erzeugen konnte. Ein Post-Editing durch einen Menschen wäre dazu notwendig. Zudem müsste bereits der deutschsprachige Ausgangstext durch ein Pre-Editing überarbeitet werden, also die Verbindungswörter „und“/„sowie“ durch „oder“ ersetzen. Das kann teuer werden!
Ein ähnliches Beispiel findet sich auch für institutionelle Mensch-Chatbot-Interaktion zwischen Klient/-innen und dem Chatbot des Missouri Department of Labour, der Fragen zwar nicht falsch beantwortet (Holste 2022b). Es bleibt aber offen, ob das Anliegen der Klient/-innen geklärt werden konnte. Diese beiden Beispiele institutioneller Interaktion lassen sich auch auf die Interaktion zwischen Kunden und Unternehmen übertragen.
Fazit
- Der Komplexitätsgrad kausaler Komplexität eignet sich, um maschinell erstellte Text zu betrachten. Für die Unternehmenspraxis: Auch Autor/-innen können ihre Texte vor der Veröffentlichung auf der Unternehmenshomepage überprüfen.
- Die Qualität maschinell übersetzter Texte oder von Chatbots ausgegebener Antworten kann bei der Anwendung in institutioneller Kommunikation auf zwei Stufen analysiert werden: Stufe 1 zum Grad, anhand derer Klient/-innen die Möglichkeit erhalten, ihr Anliegen zu klären; Stufe 2 zur Rechtssicherheit der maschinell erstellten Texte.
- Datenbasierte Systeme (auch KIs) können keine rechtssicheren Texte erzeugen. Diese übersetzten Texte (Translate) lassen sich aber durch das Pre- und Post-Editing eines Menschen rechtssicher machen. Um rechtssichere Texte in einer Maschine auszugeben, eignen sich eher regelbasierte Systeme.
- Die Nutzung automatisch erzeugter Texte ist auf die Akzeptanz durch die Nutzer/-innen in Abhängigkeit von deren Erwartungen angewiesen. Erfüllt die Maschine die Erwartungen der Klient/-innen, ermöglicht dies die Zufriedenheit der Klient/-innen – Inverses gilt, wenn die Maschine die Erwartungen enttäuscht. Weil sich dieser kommunikative (Miss-)Erfolg indirekt auf die Imagefunktion der Unternehmensmarke auswirkt, sollte der Einsatz solcher Maschinen wohlüberlegt sein und vor deren Einsatz sehr gut getestet werden.
Literatur
Engberg, J., & Heller, D. (2020). Rechtliches Wissen auf einer institutionellen Webseite – Eine Fallstudie zu sprach- und wissensorientierten Techniken der Popularisierung von Wissen im Netz. In K. Beckers, & M. Wassermann, Wissenskommunikation (pp. 64-110). Frankfurt u. a.: Peter Lang.
Hoeren, T. (2018): Internetrecht. 3., neu bearbeitete Auflage. Berlin/Boston/ De Gruyter Studium.
Holste, A. (2022a): Automatisch erzeugte Translate im E-Government. In: Agnetta, M./Dalkeranidou, S. (Hg.): Übersetzung für/von Laien. Perspektiven auf die Laientranslation und Laientranslatologie in der Romania. Band zur Tagung vom 4.10. bis 7.10.2021 in Hildesheim. Hildesheim: Olms & Universitätsverlag.
Holste (2022b): Knowledge Construction in Human-bot Interaction. Language Based Knowledge Asymmetries in the Domain of e-Government. In J. Engberg, A. Fage-Butler, & P. Kastberg (eds.), Perspectives on Knowledge Communication: Concepts and Settings. London: Routledge (submitted).
Jurafsky, D. & Martin, H. (2020): Speech and Language Processing. An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Verfügbar: https://web.stanford.edu/%7Ejurafsky/slp3/ed3book.pdf
Kastens, I. E. / Lux, P. G. C. (2014): Das Aushandlungs-Paradigma der Marke. Den Bedeutungsreichtum der Marke nutzen. Wiesbaden: Springer Gabler.
Lotze, N. (2019). Psycholinguistik in der KI-Forschung – Beeinflussen Künstliche Intelligenzen unsere Art zu kommunizieren? Psycho-Linguistic Approaches in AI Research – Do Artificial Intelligences Affect Our Way of Communicating? Psychologie in Österreich, 4. 310-316.
Schubert, K. (2007). Wissen, Sprache, Medium, Arbeit. Forum für Fachsprachen-Forschung, Band 76. Tübingen: Gunter Narr.
Wendland, K. (2020). Wird die Krone der Schöpfung auf ein neues Haupt gesetzt? Bewusste KI-Systeme im Fokus technischer Entwicklungen. In R. Fürst, Digitale Bildung und Künstliche Intelligenz in Deutschland. (Vol. AKAD University Edition, pp. 221–240). Wiesbaden: Springer.
Stadt Düsseldorf (2021, 10 02): Infos und Hilfe zu Corona. Frei verfügbar unter: https://corona.duesseldorf.de/schnell/aktuelle-regeln#



Vielen Dank für den interessanten Beitrag und den umfangreichen Quellenangaben zum Weiterlesen.
Das maschinelle Lernen durch Rückkopplung ist hier spannend: Antworten von Kunden werden dazu kategorisiert und das Programm reagiert darauf, sichert sich dann wieder ab, ob es auf dem richtigen Weg ist. Das machen die tec Riesen andauernd. Ich bin gespannt, wo das hinführt.
Alexander Jagsch, vielen Dank für Ihren Hinweis. Ich bin ebenfalls fest davon überzeugt, dass Maschinen durch die beschriebene Rückkopplung einen großen Lernfortschritt machen, und ich bin auf die weiteren Entwicklungen gespannt – diese sind z. B. bereits bei der Übersetzungsqualität von DeepL mittels Nutzer-Rückkopplung sichtbar. Aber auch DeepL kann keine Rechtssicherheit erreichen: Denn bei dieser offenen Feedbackmethode durch die Nutzenden (ohne deren Verifizierung als Expert*innen) kann die Qualität der Maschine maximal die Rechtssicherheit bei übersetzten Dokumenten erreichen, die z. B. Wikipedia bietet. Dies gilt auch im einsprachigen Bereich für Chatbots, die stellvertretend für ein Unternehmen/eine Behörde Auskunft geben. Natürlich ist ein Disclaimer wie „Die Auskunft der Maschine sind nicht rechtssicher.“ oder ähnlich denkbar.